Improve the quality of your OCR information extraction
Roadmap to get better results from Tesseract

Optical character recognition (OCR) is the electronic conversion of images of text into machine-encoded text. It is widely used as a form of data entry in many industries. Tesseract is an open-source OCR engine, it is considered one of the most accurate OCR engines available for various operating systems, Tesseract can be used directly via command line, or with wrappers for different programming languages via its API. Now available in version 5 which was released in 2021 with more features and better performance.
In this article I’m going to share what I do to improve the quality of Tesseract output, I have been exploiting Tesseract for years and I learned a lot, so I decided to share my experience. I’m going to talk about perspectives that you need to consider to get the best out of Tesseract:
- Control the input
- Image preprocessing
- Tesseract options
- Custom training Tesseract
- Text postprocessing
1. Control the input
OCR is a hard problem for any machine, and the quality of the input (image) impacts the output of the Tesseract engine. I will talk more about ways to improve the quality of the image to be better processed by Tesseract, but the pre-processing methods will naturally add more processing time to the overall information extraction pipeline, and in a lot of cases, they are not accurate and could have the opposite effect, meaning; they can degrade the quality of the image hence the output of your OCR. It is also difficult to decide when to use them and when there is no need, some methods like noise removal are not generic to every type of image. So the best way, if possible, is to improve the image acquisition, which means, you need to analyze the way you acquire the image and see if you can improve it, so you need to architect your system in a way that controls the input.
Let’s say you have a mobile application that captures user’s documents, then you wanna add some quality control in your application, like the focus, illumination, background, frame, angle, etc. You can also instead of scanning documents issued from a machine (well-formatted document), send the document in pdf format directly to the other service where it can directly be processed. You can also educate the person or people who capture those images about why the quality matters.
Of course, in a lot of cases, you don’t have control over how the image is going to be captured. That’s when you will have to preprocess the images before passing them to Tesseract to read them.
2. Image Preprocessing
Tesseract does various image processing operations internally using the Leptonica library before running the OCR. But in some cases, it isn’t enough to get good accuracy results or any results at all. There are many methods of preprocessing, I cannot include them all, but I’m going to talk about the well-known ones that are frequently used for image processing tasks.
Rescaling
Tesseract works best on images with a Dot Per Inch (DPI) of at least 300 dpi, so it might be better to resize images before passing it to Tesseract. You have to consider the resolution as well as point size. Accuracy drops off below 10 pt x 300dpi, rapidly below 8pt x 300dpi. A quick check is to count the pixels of the x-height of your characters (X-height is the height of the lower case x). At 10pt x 300dpi x-heights are typically about 20 pixels, although this can vary dramatically from font to font.
Below an x-height of 10 pixels, you have very little chance of accurate results, and below about 8 pixels, most of the text will be “noise removed”. As you can see the result after the resize is accurate vs before.


Here I used OpenCV to resize the image x2 like:

Image binarization
Image binarization or thresholding is an image segmentation method to convert the image into black and white only. Tesseract does this internally using Otsu algorithm, and now in version 5 two binarization methods are used: Adaptive Otsu and Sauvola. But still, it doesn’t work well when the page background is of uneven darkness. Below is code example using the OpenCV threshold method:
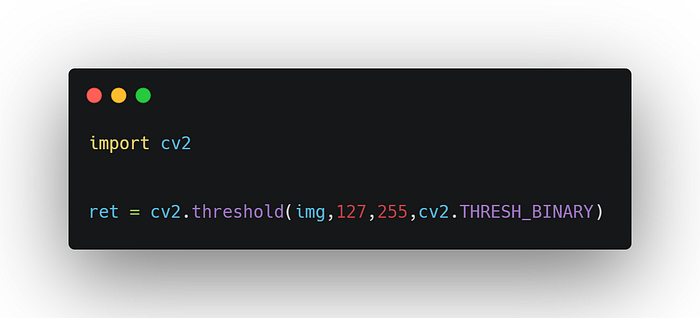
The result of Tesseract was improved, as you can see below a lot of the noise was removed and more text was detected.

Image noise reduction
Noise is a random variation of brightness or color in an image, it is usually added when we scan documents, The noise makes the text of the image extremely difficult to read for OCR engines. Certain types of noise cannot be removed by Tesseract in the binarisation step, which can cause accuracy rates to drop.

Here, I used the Rudian-Oshed-Fatemi (ROF) algorithm, you can find the implementation here. The de-noise is not an easy problem to solve but you can find many proposals that fit your requirements.
Image rotation or deskewing
A skewed image is when a page has been scanned when not straight. The quality of Tesseract’s line segmentation reduces significantly if a page is too skewed, which severely impacts the quality of the OCR. So we need to rotate the page image so that the text lines are horizontal. The first challenge here is to figure out the angle of rotation, then you need to rotate the image without damaging to text. Here is a code example using OpenCV in python.
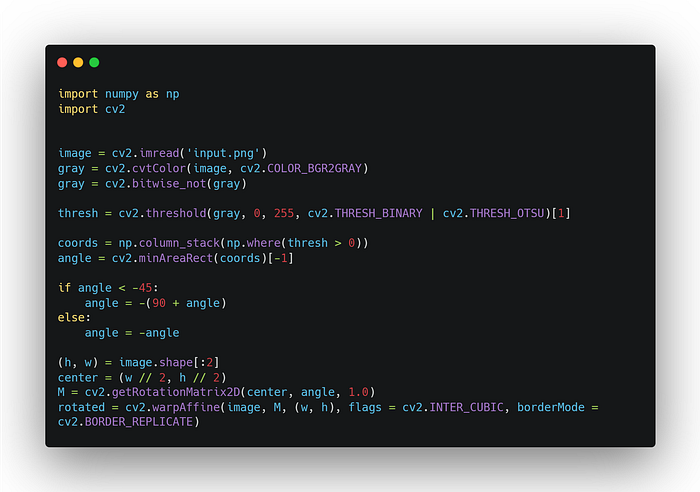

Border and background removal
Scanned pages often have dark borders around them. These can be erroneously picked up as extra characters, especially if they vary in shape and gradation. For other images that are captured via camera, we often have backgrounds that can also be picked by the OCR as characters. In the context of documents, it is better to add a layer that segments the document in an image and removes its background or border.

For this problem of background removal, you can use geometric shape detection methods, if we assume that the document is a rectangle. You can also train your machine learning model that recognizes and crop the documents in the image.
Alpha channel or transparency
Some image formats can have an alpha-channel to provide a transparency feature. Bad news for Tesseract 3.0x, because it expects the user to provide an image with no alpha-channel, although Tesseract 4.00 and above have an automated alpha-channel removal with Leptonica by blending the transparent image with a white background. But this might be a problem for images with white text like movies subtitles. So the best practice is to remove the alpha-channel before passing the image to Tesseract. You can use ImageMagick to do so.
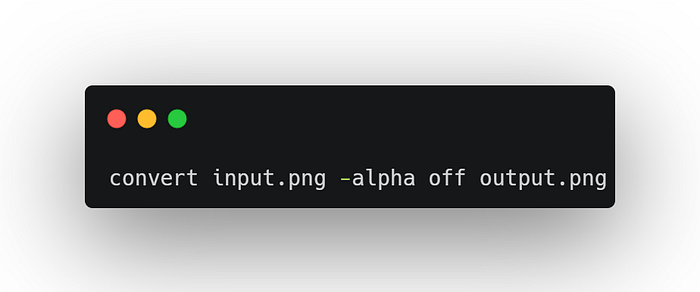
3. Tesseract options
I reviewed some code implementations of Tesseract and I noticed that many developers do not exploit some Tesseract options that can change the output. So I thought that I should mention two options that I use a lot. You can check all the options with --help-extra .
Page segmentation ( psm)
By default, Tesseract expects a page of text when it segments an image. If you’re just seeking to OCR a small region or an entire line. You can set Tesseract to only run a subset of layout analysis and assume a certain form of an image, try a different segmentation mode, using the --psm argument. The available options are:
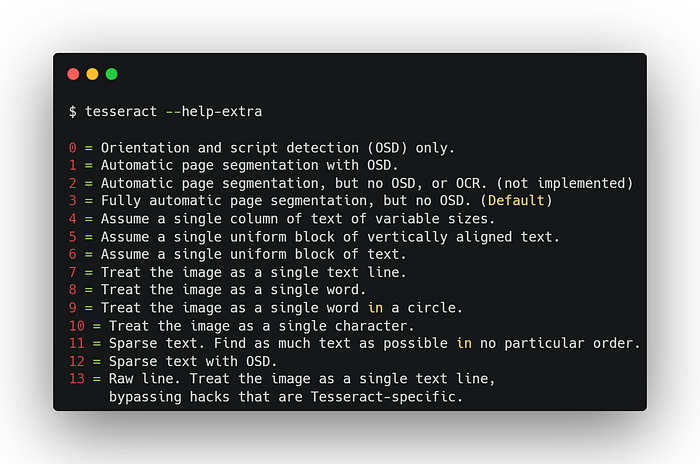
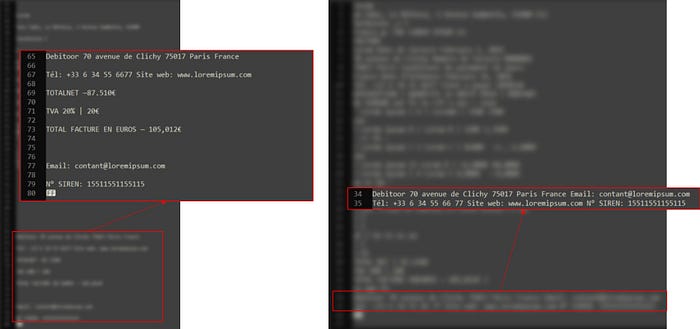
To explain to you why this matters a lot. Below is a document I want to read. I’m willing to run an NLP model after the text extraction, so I need to have the text read line by line to keep the encoded semantic information. For example, If I'm looking for ‘total price’ in a document filed with prices, then I need to keep the label ‘total price’ right before the price that represents that.

I tester to run Tesseract on my image document with no psm vs with psm 6 (Assume a single uniform block of text)
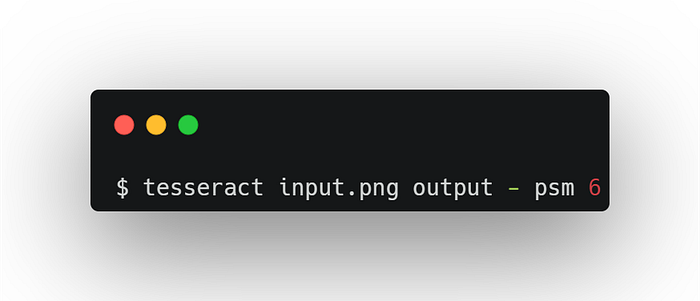
As you can see below, the output of Tesseract changed, in the left picture I had a txt file with 80 lines and a lot of spaces, while I got 36 lines in the txt file, with the two lines I need perfectly aligned. Which will later help me in my NLP model.
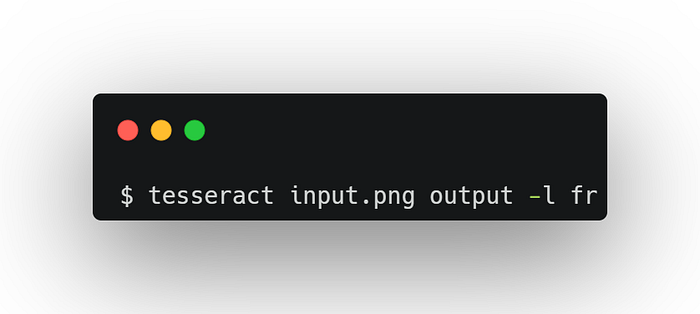
Language (l)
The language or script to use. If none is specified, eng (English) is assumed. Multiple languages may be specified, separated by plus characters. Selecting a language automatically also selects the language-specific character set and dictionary (word list). This is very important if you are working with non-English text. But I should mention that Tesseract works best with the English language.
4. Custom training Tesseract
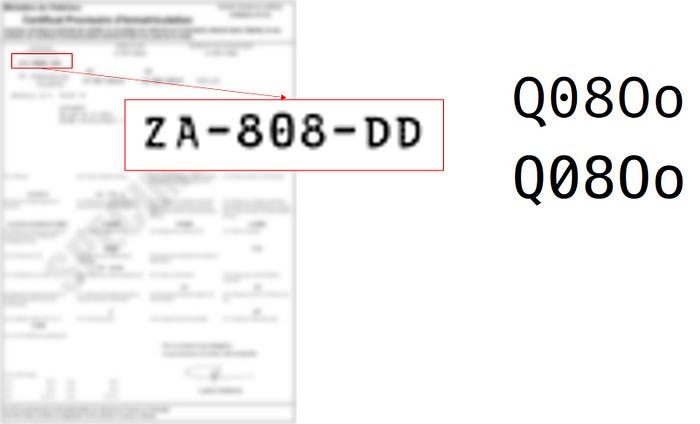
Tesseract is a powerful engine trained on a huge dataset. But sometimes the output might not be accurate although the image quality is great. I once had to deal with a font that tesseract couldn't read, it was an old Latin font, with zeros with slashes and dots, Tesseract was enabled to distinguish between a 0, 8, o, and Q. But fortunately, I had a huge dataset of Images with the font. So I was able to train a new model and add it to Tesseract.
5. Text postprocessing
If Tesseract output is not as accurate as it should be and you don’t have the option to train Tesseract you can manually improve the output, what I mean by that is that you can apply for compensations if the error is frequent and you know the patterns of the expected output. Let me give you an example, in the picture above, let’s see that the correct output is ZA-808-DD but Tesseract returns ZA-8o8-DD , meaning, it read the zero as O, if you know the pattern (you can use Regex) that governs that region of interest then you can manually add a correction layer. let’s say you know that between the two - we will always have numbers, then any alphabet should be transformed (O=>0). Of course, this method is limited when you don’t know the patterns of the expected output nor the corrections to add. Another method of postprocessing is to use NLP correctors, you can find some ready-to-use tools and libraries that can automatically correct the spelling in a text hence the output of Tesseract.
I hope this article was helpful.
Enjoy 🖖.
